




During the IPDPS 2022 in Lyon, Niels Gleinig, Maciej Besta, and Torsten Hoefler from ETH Zurich had the opportunity to present their paper titled “I/O-Optimal Cache-Oblivious Sparse Matrix-Sparse Matrix Multiplication“, published in the Proceedings of the 36th IEEE International Parallel and Distributed Processing Symposium.
IEEE International Parallel and Distributed Processing Symposium (IPDPS) is an international forum for engineers and scientists from around the world to present their latest research findings in all aspects of parallel computation.
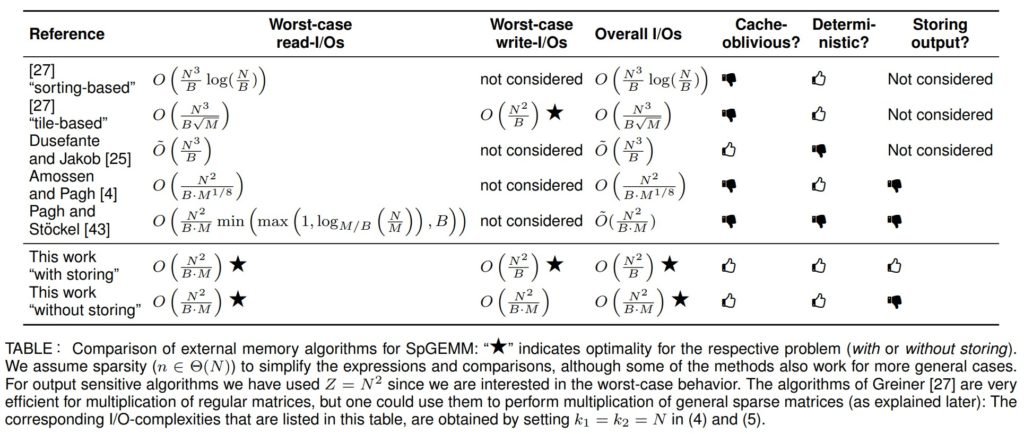
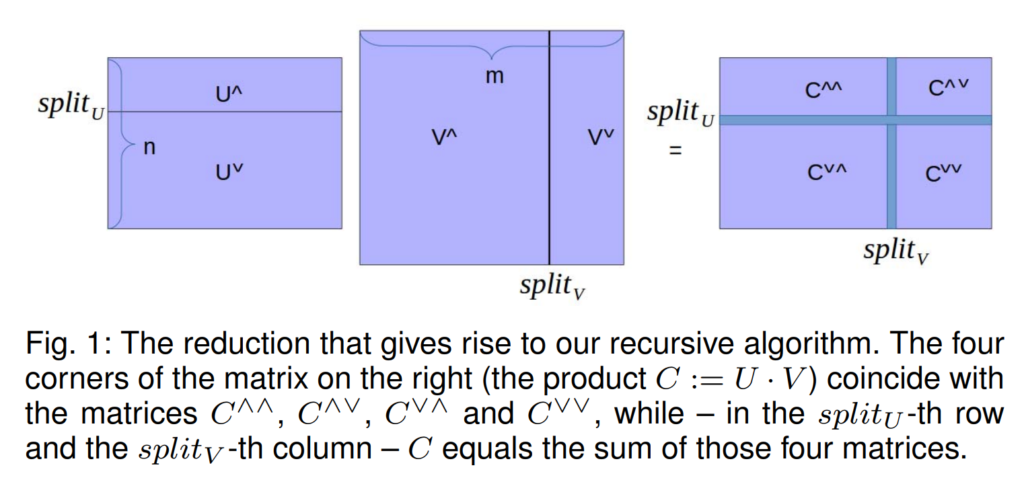
“In their conclusion, they argued that a critical observation and the basis of their algorithm is that the multiplication of two sparse matrices can be reduced to four multiplications of (appropriately preprocessed) half-sized sparse matrices and two vector additions. A recursion on this decomposition form is their algorithm’s core part. Contrary to several existing schemes, their approach is simple and deterministic. They believe that their recursive decomposition of SpGEMM may be used to tackle other problems related to minimising I/O-communication.
In the analysis of their algorithm, they distinguish between the complexity of I/O-reads and I/O-writes. They extend a current research line on “asymmetric read and write costs” that is motivated by the inherent differences in the demand for conducting reads and writes in algorithms and the differences in the cost of reads and writes in most architectures.
They mentioned that their algorithm comes with many direct use cases. They broadly discuss its applicability to graph computations and one concrete example. They apply the algorithm to improve the state-of-the-art solution to the 2- vs 3-sparse-diameter problem on sparse and directed graphs.”
The results mentioned above are one more step toward the project’s goal of creating accelerators –designed, implemented, manufactured, and deployed in Europe – to power pre-exascale systems.
Please read the complete publication here.