




Researchers have found that state-of-the-art approaches to compute convolutions CPU’s supporting SIMD instructions deliver poor performance when operating on long SIMD architectures. It was almost caused by the large memory footprints and memory access patterns with poor locality, and cache conflict misses.
In this way, the research team formed by Alexandre de Limas Santana, Adrià Armejach and Marc Casas presented a paper at the PPoPP ‘23 held in Montreal, Canada, proposing two novel algorithms in order to run these convolution workloads on long SIMD architectures efficiently. Doing this, it is possible to avoid these two mentioned issues before state-of-the-art approaches.
Two new proposals
One of the first algorithms proposed is the Bounded Direct Convolution. This prevents memory access patterns from triggering a large number of cache misses. It throttles down the register-blocking optimization while still exposing enough computation to avoid stalling the floating-point functional units.
On the other hand, the Multi-Block Direct Convolution (MBDC) algorithm improves the memory access pattern with a redefinition of the tensor memory layout. This action eliminates the possibility of cache conflict misses entirely.
For these, the team uses a code generation engine for BDC or MBDC tailored code to the needs of each convolution workload and architecture. Those two proposals are judiciously limiting the amount of computation exposed to the SIMD units and adjustments to the tensor memory layout, respectively. In this way, it has been tested in NEC’s SX-Aurora system, which features CPUs with 16,384-bit SIMD registers.
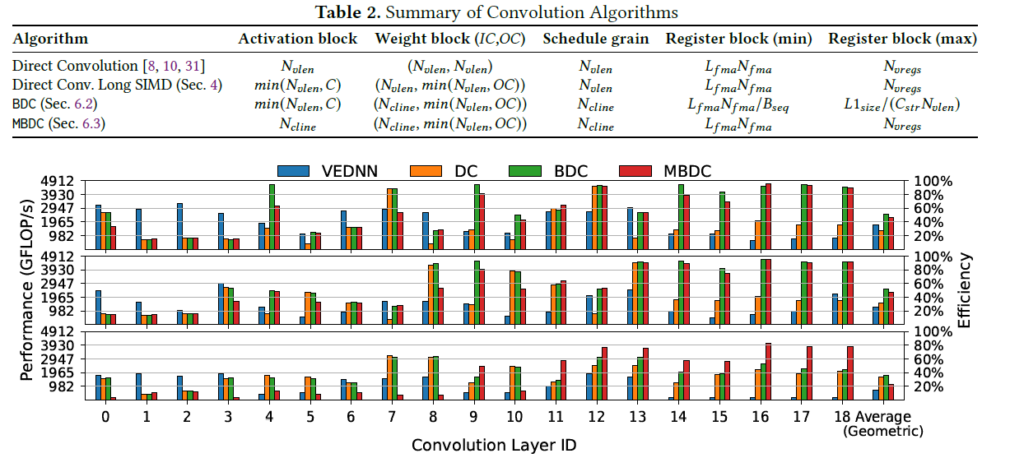
Performance of the convolution algorithms during the forward data (on the top) and backwards data (in the middle), and backwards weights (bottom) directions with a minibatch size of 256.
Before this evaluation, the research team demonstrated that previous approaches to run convolution kernels on SIMD architectures deliver poor performance when applied to processors employing long SIMD instructions. This fact is related in the paper directly with cache conflict misses. These two approaches optimise this and improve the memory access pattern, and mitigate such events.
This represents an important step in the EuPilot project’s aim to contribute to achieving a sustainable exascale HPC supply ecosystem in Europe and ensuring European technological autonomy in this field,